

مقدار T-Value و مقدار P-Value در آزمون فرض آماری چیست؟

1- مفدمه بر آزمون فرض آماری
مطابق با الزامات استانداردهای ISO 15189:2022 و ISO/IEC 17025:2017 آزمایشگاه باید یک روش اجرایی برای پایش اعتبار نتایج، داشته باشد. دادههای به دست آمده باید به نحوی ثبت شوند که روند آنها قابل تشخیص باشد. در جایی که قابل اجرا است از فنون آماری در بازنگری نتایج استفاده شود. در بسیاری از مراکز آزمایشگاهی از آزمونهای فرض آماری برای کنترل کیفیت نتایج آزمون، تحلیل نتایج مقایسات بین آزمایشگاهی و یا صحه گذاری روشهای آزمون برای برآوزدهسازی الزامات استاندارد ایزو 17025 و استاندارد ایزو 15189 استفاده میشود. اگر کارکنان آزمایشگاه و یا پژوهشگران با علم آمار آشنایی نداشته باشند و به دنبال استفاده از از نرم افزارهای آماری مانند minitab, spss و … برای تجزیه و تحلیل نتایج خود باشند، در مواجه با خروجیهای این نرم افزارها احساسی شبیه احساس آلیس در سرزمین عجایب را پیدا خواهند کرد. ناگهان آنها با یک دنیا فانتزی که در آن عبارات عجیب و مرموزی وجود دارد، روبه رو میشوند. به عنوان مثال ظهور مقادیر T و P را در انجام آزمون فرض t-test را در نظر بگیرید. در مشاهد این خروجی شما ممکن است بسیار متعجب شوید!!

این مقادیر واقعاً چیست؟ آنها از کجا بدست آمدهاند؟ حتی اگر شما از مقدار P-value برای تفسیر آماری نتایج خود به دفعات بسیار زیاد استفاده کرده باشید، باز هم ممکن است منشا واقعی آن ممکن هنوز برای شما گنگ باشد.
2- مقادیر P value و t-value در آزمون T-Test
مقدار P value و مقدار t-value به طور جدایی ناپذیری با هم مرتبط است. آنها به صورت خیلی مشابه در کنار هم نتایج تجزیه و تحلیل آماری ظاهر میشوند. هنگامی که شما آزمون t-test را انجام میدهید، معمولا برای پیدا کردن شواهدی از یک اختلاف معنی داری در میان دو جمعیت (۲-sample t) و یا بین یک جمعیت مقدار هدف (۱-sample t) هستید. به عنوان مثال در مقایسه بین آزمایشگاهی به دنبال آن هستیم که ببینم نتایج بدست آمده در دو آزمایشگاه مختلف بر روی یک نمونه یکسان بایکدیگر اختلاف معناداری دارند یا نه؟
مقدار t اندازه تفاوت را نسبت به تغییرپذیری بدست آمده از نمونهها را میسنجد. به عبارت دیگر، T برابر با تفاوت محاسبه شده تقسیم بر خطای استاندارد (SE MEAN) است. هر چه مقدار T (چه در جهت مثبت و چه در جهت منفی) بزرگتر باشد احتمال بیشتری برای رد فرض صفر به وجود خواهد آمد و هر چه مقدار T به صفر نزدیکتر باشد احتمال بیشتری برای پذیرش فرض صفر وجود خواهد داشت. (فرض صفر یعنی تفاوت معنیداری وجود ندارد.)
بخاطر داشته باشید که مقدار t که در خروجی نرم افزار نشان داده شده است بر اساس تنها یک نمونه که به صورت تصادفی از کل جمعیت گرفته شده، محاسبه می گردد و اگر نمونهبرداری تصادفی را مجدداً انجام دهید ممکن است مقدار t کمی متفاوت از آنچه قبلا محاسبه کردهاید، بدست آید. حال این سئوال مطرح میشود که در بسیاری از نمونه های که به صورت تصادفی از یک جمعیت یکسان گرفته میشود، چقدر تفاوت در مقدار t انتظار داریم که به وجود آید؟ و چگونه مقدار t بدست آمده از داده های مربوط به نمونه خود را نسبت به مقدار t مورد انتظار مقایسه کنیم؟ این کار را میتوان با رسم یک توزیع t انجام داد.
3- استفاده از یک تابع توزیع t برای محاسبه احتمال
به عنوان مثال فرض کنید که با استفاده از یک آزمون فرض آماری به روش ۱-sample t-test می خواهید تعیین کنید که یک ویژگی در جمعیت مورد مطالعه بزرگتر از یک مقدار مشخص میباشد یا خیر؟
در این مثال مقدار مشخص ۵ در نظر گرفته شده که از یک نمونه با ۲۰ مشاهده بدست آمده است. همانطور که در شکل بالا نشان داده شده مقدار t در خروجی نرم افزار minitab برابر با ۲٫۸ بدست آمده است. لذا میخواهیم ببینم در یک تابع توزیع T با درجه آزادی ۱۹ (درجه آزادی برابر است با تعداد مشاهدات منهای یک) احتمال آنکه مقدار t برابر با ۲٫۸ شود چقدر است. برای انجام این کار از نرم افزار minitab می توان استفاده نمود بدین منظور در این نرم افزار مسیر زیر را طی می کنیم:
In Minitab, choose Graph > Probability Distribution Plot.
Select View Probability, then click OK.
From Distribution, select t.
In Degrees of freedom, enter ۱۹.
Click Shaded Area. Select X Value. Select Right Tail.
In X Value, enter 2.8 (the t-value), then click OK.
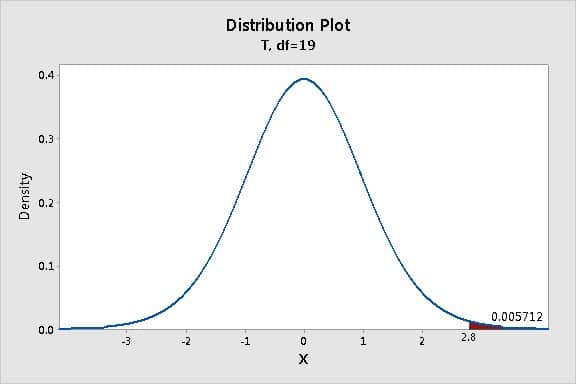
بیشترین مقدار مورد انتظار برای t محلی است که قله گراف بالا قرار دارد (یعنی مقدار صفر). این بدان معنا است که در بیشتر واقع انتظار میرود که مقدار t=0 شود. علت این امر آن است که وقتی یک نمونه به صورت تصادفی از یک جامعه برداشته می شود انتظار می رود که اختلافی بین میانگین نمونه با میانگین جامعه وجود نداشته باشد یعنی به احتمال زیاد اختلاف بین میانگین نمونه و میانگین جامعه نزدیک به صفر است.
4- مجاسبه مقدار T-Value و مقدار P-Value
احتمال اینکه مقدار T-value (چه در جهت مثبت و چه در جهت منفی) در آزمونهای فرض آماری مقدار بزرگی شود خیلی کم است. یعنی آنکه هر چه از مقدار صفر در هر دو جهت دور می شویم احتمال رخداد چنین وضعیتی به صورت طبیعی کاهش می یابد. به عنوان مثال ناحیه قرمز مشخص شده در منحی فوق احتمال اینکه مقدار T-Value برابر با ۲٫۸ و بیشتر از آن باشد را نشان میدهد. احتمال این امر ۰٫۰۰۵۷۱۲ محاسبه شده است که اگر آن را گرد کنیم برابر با ۰٫۰۰۶ می شود که به این مقدار P-Value گفته می شود.
به عبارت دیگر، احتمال به دست آوردن T-Value برابر با ۲٫۸ و یا بالاتر، زمانی که نمونه برداری از جمعیت یکسان (در مثال، یک جمعیت با میانگین ۵ در نظر گرفته شده)، حدود ۰٫۰۰۶ است.
چقدر احتمال این رخ داد وجود دارد؟ این رخداد مثل آن است که در برداشت تصادفی از ۵۲ برگ در بازی پوکر ۲ برگ تک پشت سر هم به دست شما برسد. شناس چنین رخدادی بسیار کم است!!

این امر که این نمونه از جامعهی با میانگین بیشتری از مقدار مشخص شده (در این مثال ۵) باشند، محتمل تر است. بعبارت دیگر: از آنجا که مقدار P-value بسیار کوچک تر از (< alpha level) است، شما فرض صفر رد و نتیجه گیری است که تفاوت معنی داری وجود دارد.
مقادیر T و P به طور جدایی ناپذیری مرتبط هستند و به سادگی میتوانید از آنها برای تصمیم در خصوص درست یا نادرست بودن یک فرض استفاده کنید. مقدار یکی از آنها بدون تغییر در دیگری، تغییر نخواهد کرد. مقادیر بزرگتر قدرمطلق T-Value منجر به مقادیر کوچکتر P-value میشود که امر سبب کاهش احتمال پذیرش فرض صفر میشود. به طور معمول مطالعات آماری در سطح اطمینان ۹۵% (یعنی آلفای برابر با ۰٫۰۵) انچام میشود.
در سطح اطمینان ۹۵% اگر P-value کوچکتر یا مساوی ۰٫۰۵ باشد فرض صفر را رد میکنند و در غیر این صورت فرض صفر را نمی توان رد کرد.
5- سخن پایانی
نکته آخر اینکه که در برخی از نرم افزارها مانند spss مقدار p-value در جدول های خروجی نرم افزار تحت عنوان Significant Level ذکر میشود. در این پست آموزشی برخی از نکات مهم برای در خصوص آزمون فرض T-TEST و مقدار P-Value ذکر شود. از آزمونهای فرض آماری کارکنان آزمایشگاه میتوانند برای پایش اعتبار نتایج آزمون و همچنین تصدیق یا صحه گذاری روشهای آزمون بر اساس الزامات استانداردهای ایزو ۱۷۰۲۵ و ایزو ۱۵۱۸۹ استفاده نمایند. در صورت وجود هر گونه پرسشی در خصوص آزمون فرض آماری و تحلیل آماری نتایج میتوایند سوالات خودتان در قسمت کامنت های این پست قراردهید سعی خواهد شد تا جای ممکن به سئوالات مطرح شده پاسخ مناسب داده شود. همچنین در صورت نیاز به برگزاری دوره های آموزشی تصدیق و صحه گذاری روش های آزمون و کنترل کیفیت داخلی و خارجی برای کارکنان آزمایشگاه یا برای دریافت خدمات مشاوره ایزو ۱۷۰۲۵ و مشاوره ایزو ۱۵۱۸۹ میتوانید با ما تماس بگیرید.
48 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.



عالی بود ممنونم کلی سوال بی جواب داشتم که شما کمک کردید
یعنی اینهمه آمار به خوردمون دادن یه طرف این توضیح یه طرف
ممنونم از توضیحات خوب شما
خیلی خوب بود توضیحاتتونن , من واسه کنکور ارشد دانشگاه علامه مصاحبه دعوت شدم این مطالب برام خیلی مفید بود.
ببخشید توspss از کجا باید p-valueرو وارد کنیم ؟
سلام. p-value را لازم نیست وارد کنید وقتی آزمون ها را اجرا کردید. گزینه ای تحت عنوان سطح معنی داری sig می دهد بر اساس آن p- Value را می نویسید. لطفا از سایت ما هم بازدید کنید. سایتی برای پرسشنامه استاندارد – تحلیل داده های آماری https://rava20.ir/
واقعا ممنون…. قبل ار توضیح زیبای شما دقیقا من همون احساس الیس در سرزمین عجایب رو داشتم
خارج از کشور واحد امار دارم . خیلی از مطالب به زبان انگلیسی نامانوس اند . پدرم درامده .یه منبع فارسی که همه مطالب اماری باشه معرفی کنید لطفا . نرم افزار آماری مون R cmander
ممنون از تفهیم p value
سلام.خسته نباشید ببخشید یه سوال داشتم .مقادیر T که در جدول رگرسیون چند متغیری به روش همزمان وجود داره رو باید با چی مقایسه کرد که متوجه رد فرض صفر یا قبول اون بشیم. البته ستون کنارش P هست ولی من میخوام از طریق T متوجه بشم نتیجه چی میشه وو اینکه یه سال دیگه اینکه قاعدتا این T با آزمون T student که برای مقایسه میانگینها هست فرق داره؟ یه سوال دیگه اینکه مقدار F در جدول تحلیل واریانس جهت ازمون معناداری مدل ارائه شده چجوری تحلیل میشه؟ با چی مقایسه میشه؟ وو چی ازش متوجه می شیم ممنون
ممنون. بعد از مدتها این قضیه به صورت اصولی در ذهن من جا افتاد
با تشکر از اطلاعات خوبتون .ممنون میشم بفرمایید اندازه عددP – VALUE در نمودار SPC چقدر باید باشد
زیر ۰٫۰۵ یا بالای ۰٫۰۵ اوکی میباشد.
با سلام و احترام
سئوال شما شفاف نیست.
اگر در تحليل تي تك نمونه اي ضرائب تي منفي شود چگونه بايد انرا تفسير كرد?
اگر در تي تك نمونه اي نتايج تي معني دار شود ، اما ميانگين ها كمتر از سه باشد، اين تناقض را چگونه مي توان توجيه وَيَا برطرف كرد
با سلام و احترام
منفی شدن مقدار آمار تی مشکل ایجاد نمی کند اگر مقدار میانگین جامعه اول کوچکتر از جامعه دوم باشد مقدار آماره تی منفی می شود.
قسمت دوم سئوال شما شفاف نیست.
Exelent
سلام ممنون از اطلاعاتتون .یک سوال من برای رسم گرادیان خطوط همباران از نرم افزار spss استفاده کردم الان میخوام p-value زا برا این اطلاعات داخلspss بدست بیارم باید چیکار کنم .کلا این نرم افزار p-value میده ؟
با سلام و احترام
در نرم افزار spss
The p-value is labeled as “Sig.” in the SPSS output (“Sig.” stands for significance level).
مو فق باشید
دستمردی
با سلام وخسته نباشید خدمت شما.میخواستم ببینم محدوده t-stat چقد باشد خوبه؟
با سلام و احترام
محدوده پذیرش برای این آزمون بر اساس سطح اطمینان و تعداد نمونه تعیین می شود
به طور معمول در سطح اطمينان 95% اگر p-value بیشتر از 0.05 باشد فرض صفر پذیرفته می شود
سلام
اگر تي تك نمونه اي معني دار نشود تبيين آن چيست
با سلام و احترام
اگر مقدار P-VALUE بزرگتر از 0.05 شود بدین معنا است که در سطح اطمینان 95% فرض صفر (عدم وجود اختلاف معنادار بین میانگین مقادیر مشاهده شده و مقدار هدف) پذیرفته میشود.
سلام ببخشید در انالیز دیناها به من یکstudent t می دهد که می خواهم بدونم همون t value هست یا خیر ؟
با سلام و احترام
یکی از خروجی های آزمون مقدار آماره t است.
موفق باشید
دستمردی
سلام..ببخشید اگر در سطح اطمینان 95% مقدار p-value دقیقا 0.0000 باشد به چه معنی است ؟ و چه باید کرد ؟
با سلام و احترام
فرض صفر قویا رد است.
باید فرض یک را پذیرفت
سلام آزمون t value چیه کلا؟ و چند باید باشه؟
با سلام و احترام
اساس این آزمون در کتاب های پایه آماری تشریح شده است. در صورت نیاز به کسب اطلاعات پایه به آنها مراجعه نمایید.
با تشکر از پاسخگویی تان، اینکه در تحلیل واریانس یک طرفه anovaکه عرض کردم .pvalue=0.000 است مقدار Fهم زیاد بدست می آید در حدود 400…آیا این عادی است؟و اینکه من چند منبع انگلیسی خوندم که pvalueرا نباید در مقاله =0.000نوشت و باید نوشت کمتر از 0.0001 لطفا نطرتون رو بفرمائید متشکرم
سلام وقتتون بخیر
من سواللی داشتم خدمتتون ممنون میشم پاسخ بفرمایید
مقدار t من در pls، مقدارش 30/1 هست. بفرمایید ایا این عدد عادی هست؟؟
و همچنین برای تایید فرضیه م p value رو از کجا بدونم؟؟ در چه سطح اطمینانی تایید میشه فرضیه م؟
ممنون میشم پاسخ بدید
با سلام و احترام
در سطح اطمينان 95% اگر p- value بزرگتر از 0.05 شود فرض صغر تایید می گردد در غیر این صورت فرض یک
سلام
من در یک واحد تولیدی تغیراتی را در فرایند کار و تولید ایجاد کردم. به همین خاطر امار حوادث نفرات کاهش پیداکرده است. تغییر روش از سال 95 صورت گرفته است. بنابراین داده های از سال 95 تا نیمه دوم 98 را داره و همین طور امار حوادث از سال 91تا95. یعنی 4 سال قبل از اصلاح روش و 4سال بعد از اصلاح روش. الان چگونه باید معنی دار بودن تغییرات را بررسی کنم؟
در این بررسی هر سال به عنوان یک مشاهد در نظر گرفته می شود؟ (8 مشاهده)
و درجه ازادی می شود 7؟
با سلام و احترام
برای پاسخ به این سوال نیاز به اطلاعات بیشتر وجود دارد
همچنین به صورتی نوشتاری نمی توان به این سوال پاسخ داد
سلام. ممنون بابت توضیح خوبتون درباره مقدار t value.
یک سوال داشتم
آیا برای مقدار t سطحی برای معنی داری ـ مثل مقدار p ـ وجود داره؟
ممنون
با سلام و احترام
بله
مقادیر بحرانی برای آزمون t در جدول آماری T-test Table آماده است.
موفق باشید
دستمردی
سوال : آلفا یا میزان ریسک خطا در تحقیقات علمی بر چه مبنایی و توسط چه کسی و چه زمانی تعیین می شود ؟
سلام در موردآلفا میشه یکم توضیح بدین
تفاوت معنی دار یعنی چی دقیقا
رد یا تاییید
با سلام و احترام
اختلاف معنی دار در میانگین نتایج یعنی از نظر آماری تفاوت مشاهده شده ناشی از خطاهای تصادفی نیست.
پیشنهاد می کنم پست زیر را مشاهده نمایید
مقادیر T-Value و P-Value در آزمونهای فرض آماری چیست؟
https://dastmardi.ir/1394/09/13/%D9%85%D9%82%D8%A7%D8%AF%DB%8C%D8%B1-t-value-%D9%88-p-value-%D8%AF%D8%B1-%D8%A2%D8%B2%D9%85%D9%88%D9%86%E2%80%8C%D9%87%D8%A7%DB%8C-%D9%81%D8%B1%D8%B6-%D8%A2%D9%85%D8%A7%D8%B1%DB%8C-%DA%86%DB%8C%D8%B3/
خیلی روان و خوب توضیح دادید
تشکر فراوان
با سلام پطور میشه نمودار را بر اساس p-value رسم کرد؟
با سلام و احترام
چه نموداری را برحسب p-value رسم کرد؟
سلام میخواسم بدونم ایا من میتونم برا تحلیل فرضیه هام دو تا سطح اطمینان ۹۵و۹۰درصد احاظ کنم ؟؟؟؟چون مقدار امار tبرای چندتا فرضیم ۱.۸۰است
با سلام و احترام
بله
سلام و عرض ادب و احترام، چرا نتایج p-value با نتایج آماره t مغایرت دارد. به عبارت دیگر ممکن است فرضیه ای با آماره t رد شود ولی با p-value قبول شود
سلام می خوام بدونم در ازمون T عدد ما ممکنه منفی در بیاد؟ یا علامت تاثیری ندارد و ما در نظر نمی گیریم؟
سلام
بله ممکن عدد t منفی بدست آید
برای تعیین اختلاف معنادار بدون علامت در نظر گرفتن تحلیل را می توان انجام داد.
با سلام و خسته نباشید.در Ttest دو مورد Bonett , levene چه مفهومی دارند؟ Pvalue اولی بالاتر از آلفا می شود و دومی پایین تر. برای سنجش P-value باید به کدوم استناد کرد؟
با سلام و احترام
در آزمون T-TEST مقادیر مربوط به P-VALUE به روش LEVENE و bontte را نمی دهد.
در آزمون مقایسه پراکندگی های دو جامعه این مقادیر ارائه می شود و در صورتی که شما در نرم افزار minitab گزینه مربوط به نرمال بودن را نزدید این مقادیر نمایش داده می شود.
در صورتی که داده های شما دارای توزیع نرمال نیست برای بررسی پراکندگی نتایج دو جامعه از مقدار p-value آزمون levene استفاده نمایید.
پیروز و سربلند باشید
دستمردی
با سلام، ممنون از اطلاعات مفیدی که در اختیار قرار دادید.
من میخوام نتایج مدلسازی که انجام دادم رو با داده های آزمایشگاهی متناظرش مقایسه کنم تا به نوعی مدلسازی رو اعتبار سنجی کرده باشم. باید از چه آزمون آماری برای مقایسه استفاده کنم بین t تک نمونه یا دو نمونه شک دارم. ممنون میشم نظرتون رو بفرمائید.
با سلام و احترام
برای اعتبارسنجی مدلسازی در بخش آنالیز رگرسیون یک گزینه داریم برای پیش بینی این گزینه را می توانید برای متعبر سازی مدل استفاده کنید. در نرم افزار minitab مسیرش را زیر گذاشتم:
Stat > Regression > Regression > predict
برای پیش بینی در نقطه مورد نظر شما بازه برای سطح اطمینان 95% را می دهد. برای متعبرسازی مدل، نتیجه آزمون آزمایشگاهی شما بایستی در این بازه قرار گیرد.
موفق باشید
دستمردی